Hello, I've been absent for a long time, a lot of things have changed for me.
I've decided to set-up a new blog using github-pages, it's far more simpler to edit and publish for me.
Long story short, here is the link: slashvar.github.io
There's already so posts: a GNU Make tutorial, some thoughts on my past life as a programming teacher and another attempt to define a good programmer !
I'll let you read, I'll try to post link to new article here to make the connexion.
On a more personal side, I'm now a software engineer at algolia.com working on their ground breaking search engine.
Saturday, April 7, 2018
Friday, October 21, 2016
Beginner's corner: Let's talk C++
Been a long time, I've got several articles under constructions for quite some times … This one wasn't planified, I just think I can share some basic but nice C++.
C++ is huge language, it's probably impossible to explore all the features in a lifetime, and trying to apprehend what theses features can bring you is probably out of reach for a normal human being. But, we can sometimes grasp some interesting ideas.
My approach of C++ is not traditional, in the sense that I'm not using C++ as an object oriented language, more like a higher-level C, objects and classes are just one of the interesting aspects. Anyway, I'll use some object here, but without inheritance and all the buzz around object design.
Power to the destructor
As in any sane language, when closing a scope, variables local to that scope dies. But, in C++ some of these local variables can be direct objects (not pointers to object like in Java) and thus, when a variable dies, the object must be destroy. This happen transparently and can easily be coded:
# include <iostream> struct S { int id; S(int i) : id(i) { std::cout << "Building S(" << id << ")" << std::endl; } ~S() { std::cout << "Destroying S(" << id << ")" << std::endl; } }; int main(void) { // Building in main std::cout << ">> main <<" << std::endl; S s1(1); { // Sub context std::cout << ">>> Sub context <<<" << std::endl; S s2(2); std::cout << ">>> Sub context last statement <<<" << std::endl; } std::cout << ">> main last statement <<" << std::endl; return 0; }
Running this piece of code shows when destructors are implicitly called.
>> main << Building S(1) >>> Sub context <<< Building S(2) >>> Sub context last statement <<< Destroying S(2) >> main last statement << Destroying S(1)
It's a classic C++ example, and if you're not familiar with this, you should start over your learning of C++ …
The real question is: what can we do with that ? Things, a lot of things …
RAII
C++ programmers should be familiar with a concept called RAII: Resource Acquisition Is Initialisation. cppreference describes RAII:Resource Acquisition Is Initialization or RAII, is a C++ programming technique which binds the life cycle of a resource (allocated memory, thread of execution, open socket, open file, locked mutex, database connection—anything that exists in limited supply) to the lifetime of an object.
You can find classical examples of RAII in STL, one of the most interesting is the std::lock_guard class. In short, at creation it locks a mutex and unlocks it when destroyed.
struct counter { unsigned c; std::mutex m; void incr() { // guard lock m when constructed std::lock_guard<std::mutex> guard(m);
c += 1; // guard get destroyed and unlock m } };
Using lock-guards greatly improves and simplifies algorithm using lock. It also provides a strong guarantee that mutexes are always unlocked when leaving a function or code block, even in the presence of exceptions. This example demonstrate how lock-guards can simplify code using mutexes, using lock-guards avoid the need of adding an unlock statement whenever you want to leave your code.
template<typename T> struct list { struct node { T data; node *next; node(): next(nullptr) {} node(T x, node *n) : data(x), next(n) {} }; node *head; std::mutex mutex; list() : head(new node()) {} /* using lock_guard */ bool member(T x) { std::lock_guard<std::mutex> guard(mutex); for (auto cur = head; cur->next; cur = cur->next) { if (cur->next->data == x) return true; } return false; } /* using explicit lock/unlock */ bool member_old(T x) { mutex.lock(); for (auto cur = head; cur->next; cur = cur->next) { if (cur->next->data == x) { mutex.unlock(); return true; } } mutex.unlock(); return false; } /* using lock_guard */ bool insert(T x) { std::lock_guard<std::mutex> guard(mutex); auto cur = head; for (; cur->next && cur->next->data < x; cur = cur->next) continue; if (cur->next && cur->next->data == x) return false; cur->next = new node(x, cur->next); return true; } /* using explicit lock/unlock */ bool insert_old(T x) { mutex.lock(); auto cur = head; for (; cur->next && cur->next->data < x; cur = cur->next) continue; if (cur->next && cur->next->data == x) { mutex.unlock(); return false; } cur->next = new node(x, cur->next); mutex.unlock(); return true; } };
Lock-guards provide coding comfort similar to synchronized blocks in Java or try-finally constructions.
The next example demonstrates another use case. The idea is to provide a simple almost non-intrusive benchmarking object. Here is the class definition:
#include <chrono> using std::chrono::duration_cast; using std::chrono::nanoseconds; using std::chrono::steady_clock; struct scoped_timer { scoped_timer(double& s) : seconds(s), t0(steady_clock::now()) {} ~scoped_timer() { steady_clock::time_point t1 = steady_clock::now(); std::chrono::duration<double> diff = t1 - t0; seconds = diff.count(); } double& seconds; steady_clock::time_point t0; };
Here is simple code usage:
double seconds; { scoped_timer clock(seconds); std::cout << "benched code blocks" << std::endl; } std::cout << "elapsed time: " << seconds << "s" << std::endl;
Once again the trick is to take advantage of the pair constructor/destructor of the object. The scoped_timer get a reference on a double and when destroyed push the time difference in this reference when destroyed.
More ?
C++ coding exercise: we want a something that behaves like the assert construction with the ability to emit a message. The use case looks like this:
log_assert(x > 0) << "hello " << x;
If the condition is true (in our case x is positive) nothings happen, but if it's false, the message gets be printed and the program exits.
Looks easy ? If you write log_assert as a function, you'll get exactly what you don't want: the message get printed only if you don't leave the program …
The expression log_assert(b) can be a call to a constructor, you see the idea now ?
As a hint, let's see what happen with our first class example if you just call the constructor without naming the resulting object:
As a hint, let's see what happen with our first class example if you just call the constructor without naming the resulting object:
int main(void) { std::cout << ">> main <<" << std::endl; S(1); std::cout << ">> main last statement <<" << std::endl; return 0; }
The output:
>> main << Building S(1) Destroying S(1) >> main last statement <<
Yes, we build the object and it get destroyed directly ! In fact, the object is created for the statement only, and thus get destroyed on the semi-colon.
So, all we need is to handle the leave on assertion in the destructor and add some overloading on the operator <<. Here is a possible implementation:
struct log_assert { bool cond; log_assert(bool c) : cond(c) {} ~log_assert() { if (cond) return; std::clog << std::endl; abort(); } template<typename T> log_assert& operator<< (const T& x) { if (!cond) std::clog << x; return *this; } };
There's probably better way to do that, but it will be enough for now …
And this why …
There's a classical trap related to this pattern when using RAII resources. A good example can be found with the std::async construction. std::async provides a lazy parallel evaluation of a function. The common mistake arises when you use it to launch a computation and don't need to wait for completion explicitly, like in the following code sample:void run(unsigned int x, unsigned int len) { for (unsigned int i = 0; i < len; ++i) printf(">> %u - %u <<\n", x, i); } int main(void) { std::async(run, 1, 100); std::async(run, 2, 100); }
The two std::async statements are not run in parallel, if you want parallelism, you need to write it that way:
int main(void) { auto w1 = std::async(run, 1, 100); auto w2 = std::async(run, 2, 100); }
On destruction the object returned by std::async wait for the completion of the submitted task, so if you don't keep alive the returned object, the execution is not parallel since it waits for the completion of the first task before passing to the second statement.
Once again, it's all about understanding when things get destroyed …
Conclusion
I've just played with very basic C++ notions, but there's a lot of applications. Understanding the dependencies and order of destruction of objects is important in C++.RAII is almost behind smart pointers, an important concept in modern C++ programming. Even if the concrete implementation of a smart pointer class is a little bit tricky, the basic concept (releasing memory when the smart pointer dies) is easy to get once you understand RAII. Among all C++ features, the automatic invocation of destructors when objects go out of scope is probably one of the most useful.
Monday, August 3, 2015
Reference counting: practice and trouble
Reference counting is a well known strategy used to provide simple garbage collection. As automatic garbage collection, it has a lot of issues among which not correctly handling circular data-structures is the most obvious.
On the other hand, used for semi-automatic GC, it is pretty accurate, easy to implement and solves probably most of the use cases. People using C++11 shared_ptr probably see what I mean.
But I'm here to talk about concurrent programming and especially non-blocking data-structures. There’s a lot of academic explaining why ref-count won't help you, but still a lot of people think that we can use ref-count without impact.
Safe world: sequential code and lock protection
The classical way of using ref-counting, in a safe context, is to store the counter in the data (the memory cell.) While the accounted pointer is reachable, the counter count at least one reference corresponding to the placeholder of the pointer and thus will never get down to 0 and, thus, memory won't be freed.
Being alone on the data (due to lock protection or simply because there’s only one thread currently running) a thread can safely increment the pointer without any risk of hazardous memory access. Even when using optimistic or lazy locking, locks may prevent conflicting increment/decrement situations.
Anyway, we can present a simple and usable ref-count in C using intrusive data structure.
Simple and generic ref-count in C
We now introduce a simple ref-count using intrusive data-structure. Intrusive data structures have been discussed in this blog in a previous post.
In our case, what we need is: a small structure containing the counter and a pointer to the delete function, an operation to increase the counter, an operation to decrease it and eventually call the delete function and finally some macro to retrieve the parent structure pointer from the pointer of our intrusive structure. Here is the basic code (without any locking support):
/* Simple ref-count */
# ifndef REF_COUNT_H_
# define REF_COUNT_H_
// needed for offsetof
# include <stddef.h>
// Intrusive tools to retrieve access to the including structure
# define containerof(TYPE_, FIELD_, PTR_) \
((TYPE_*)((char*)(PTR_) - offsetof(TYPE_, FIELD_)))
// Typedef for the delete function pointer
// increase readability
typedef void (*delete_ptr)(void *);
// The ref-count intrusive structure
struct ref_count {
unsigned counter;
delete_ptr deleter;
};
// Init function, set the counter to 1
static inline
void ref_count_init(struct ref_count *ref, delete_ptr ptr) {
ref->counter = 1;
ref->deleter = ptr;
}
// Increasing count
static inline
void ref_count_get(struct ref_count *ref) {
ref->counter += 1;
}
// Decreasing count
// call deleter if count get downto 0
static inline
void ref_count_release(struct ref_count *ref) {
ref->counter -= 1;
if (ref->counter == 0)
ref->deleter(ref);
}
# endif /* REF_COUNT_H_ */
And, because that’s better with usage example:
// Testing our ref-count
# include <stdio.h>
# include <stdlib.h>
# include "ref_count.h"
// Some data
// last field ref is our ref-count intrusive structure
struct data {
int an_int;
float a_float;
struct ref_count ref;
};
// Now the delete function
void data_delete(void *p) {
struct data *main_struct;
main_struct = containerof(struct data, ref, p);
free(main_struct);
}
// A builder for our data
struct data* new_data(int a, float b) {
struct data *d;
d = malloc(sizeof (struct data));
d->an_int = a;
d->a_float = b;
ref_count_init(&(d->ref), data_delete);
return d;
};
// A toy function using the data
void do_some_stuff(struct data *d) {
// Holding the pointer, get it !
ref_count_get(&(d->ref));
printf("Data (%p) : %d %g\n", d, d->an_int, d->a_float);
// We're done, release the pointer
ref_count_release(&(d->ref));
}
// run using valgrind or clang's address sanitizer to check for memory leaks.
int main() {
struct data *d;
d = new_data(42, 3.14); // count already set to 1
do_some_stuff(d); // get and release
do_some_stuff(d); // get and release
ref_count_release(&(d->ref)); // we're done
return 0;
}==20934== Memcheck, a memory error detector ==20934== Copyright (C) 2002-2013, and GNU GPL'd, by Julian Seward et al. ==20934== Using Valgrind-3.10.1 and LibVEX; rerun with -h for copyright info ==20934== Command: ./testing ==20934== Data (0x51d8040) : 42 3.14 Data (0x51d8040) : 42 3.14 ==20934== ==20934== HEAP SUMMARY: ==20934== in use at exit: 0 bytes in 0 blocks ==20934== total heap usage: 1 allocs, 1 frees, 24 bytes allocated ==20934== ==20934== All heap blocks were freed -- no leaks are possible ==20934== ==20934== For counts of detected and suppressed errors, rerun with: -v ==20934== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 1 from 1)
Of course, this implementation is not thread safe. Having a safe locking mechanism protecting the ref-count is not that easy and is outside of the scope of this article.
More complete example: data in 2 containers
Here I provide an example using intrusive lists as containers and where data chunks belong to two lists at the same time. Follow code comments:
First the intrusive list implementation:
// list.h : Basic intrusive lists
# ifndef LIST_H_
# define LIST_H_
# include <stddef.h>
// No explicit ref-count, but we need containerof
# include "ref_count.h"
struct list {
struct list *next, *prev;
};
// Init circular double linked list
// Used to init sentinel
static inline
void list_init(struct list *l) {
l->next = l->prev = l;
}
// list is empty
static inline
int list_is_empty(struct list *l) {
return l->next == l;
}
// Insert before current node
static inline
void list_insert_before(struct list *entry, struct list *cell) {
cell->next = entry;
cell->prev = entry->prev;
entry->prev = cell;
cell->prev->next = cell;
}
// Insert after current node
static inline
void list_insert_after(struct list *entry, struct list *cell) {
cell->prev = entry;
cell->next = entry->next;
entry->next = cell;
cell->next->prev = cell;
}
// Detach current node
static inline
void list_detach(struct list *entry) {
entry->prev->next = entry->next;
entry->next->prev = entry->prev;
entry->next = NULL;
entry->prev = NULL;
}
// Foreach tools
// Simple foreach
// entry = list entry point (sentinel)
// cur = variable used as iterator, only active in loop
# define list_foreach(entry, cur) \
for (struct list *cur = entry->next; cur != entry; cur = cur->next)
// deque like interface
// should be used only with sentinel as input
// mainly wrappers
// deque is empty
int deque_is_empty(struct list *entry) {
return entry->next == entry;
}
// Push front
static inline
void deque_push_front(struct list *entry, struct list *elm) {
list_insert_after(entry, elm);
}
// Push back
static inline
void deque_push_back(struct list *entry, struct list *elm) {
list_insert_before(entry, elm);
}
// Getting (not detached) front cursor
// return NULL if empty
static inline
struct list* deque_front(struct list *entry) {
if (deque_is_empty(entry)) return NULL;
return entry->next;
}
// Getting (not detached) back cursor
// return NULL if empty
static inline
struct list* deque_back(struct list *entry) {
if (deque_is_empty(entry)) return NULL;
return entry->prev;
}
# endif /* LIST_H_ */
And now the code:
// Demonstration of intrusive lists and ref-count
# define _XOPEN_SOURCE 500
# include <stdlib.h>
# include <stdio.h>
# include "list.h"
# include "ref_count.h"
// Kind of a selection sort
// we look for the smallest element in a list and push it in front of the
// deque but only if it is not already there
// After building the deque, we remove clear the original list, then print the
// content of the deque and finally clear it also
// Data: simple int
// Data structure: each element belongs to 2 lists and has a ref-count
struct data {
int val;
struct list main_list;
struct list deque;
struct ref_count ref;
};
// Now the delete function
void data_delete(void *p) {
struct data *main_struct;
main_struct = containerof(struct data, ref, p);
free(main_struct);
}
// For simplicity we put almost everything in a single function
// sentinel for each list are local entity, and thus automatically freed
void example(size_t len) {
// Sentinels
struct list list_entry;
struct list deque_entry;
// Building the list
list_init(&list_entry);
for (size_t i = 0; i < len; i++) {
struct data *cell = malloc(sizeof (struct data));
cell->val = random() % 100;
// init ref counting, no need to account current copy
ref_count_init(&(cell->ref), data_delete);
list_insert_after(&list_entry, &(cell->main_list));
}
// Display the list
list_foreach((&list_entry), iter) {
struct data *cell;
cell = containerof(struct data, main_list, iter);
printf("%02d->", cell->val);
}
printf("end\n");
// Starting the sort
// iterate over the list to find smallest element
// add the cell in the deque if it is not already thre
// lastval in order to avoid the same value again and again
// No negative entry, use -1 as initial value
int lastval = -1;
list_init(&deque_entry);
for (size_t i = 0; i < len; i++) {
struct data *min = NULL;
int minval = 100; // maximum possible value
list_foreach((&list_entry), iter) {
struct data *cell;
cell = containerof(struct data, main_list, iter);
if (cell->val > lastval && cell->val < minval) {
min = cell;
minval = min->val;
}
}
if (min != NULL && min->val > lastval) {
// Add an element
ref_count_get(&(min->ref));
deque_push_back(&deque_entry, &(min->deque));
lastval = min->val;
}
}
// Display the deque
list_foreach((&deque_entry), iter) {
struct data *cell;
cell = containerof(struct data, deque, iter);
printf("%02d->", cell->val);
}
printf("end\n");
// Clear the main list
while (!list_is_empty(&list_entry)) {
// Extract next element
struct list *iter = list_entry.next;
list_detach(iter);
// No more ref in the list
ref_count_release(&(containerof(struct data, main_list, iter)->ref));
}
// Display the deque
list_foreach((&deque_entry), iter) {
struct data *cell;
cell = containerof(struct data, deque, iter);
printf("%02d->", cell->val);
}
printf("end\n");
// Now clear the deque
while (!deque_is_empty(&deque_entry)) {
struct data *cell;
cell = containerof(struct data, deque, deque_front(&deque_entry));
list_detach(&(cell->deque));
// No more ref in the list
ref_count_release(&(cell->ref));
}
}
int main() {
example(10);
return 0;
}
Once again, the code runs without any memory leak (try with valgrind … )
Trying to be non-blocking
Obviously, using ref-counting in a multithreaded context requires locks.
The legitimate question is: if we use atomic integer for the counter and we limit the usage of our ref-count to some safe situation, can we have non-blocking ref-count ?
Safe Concurrent Ref-counting ?
Let’s consider the following case: we have a pointer between shared between a group of reader threads and a single updater thread, updates are only performed by replacing the pointer, not modifying the content. This is, basically, the traditional example used to illustrate RCU.
During the update, the writer thread first get the pointer, allocate a new one, eventually copy the old data in the new allocated area and when ready atomically replace the old pointer with new one. Once the pointer has been replaced, no readers can access it, and the writer can then wait for readers still active on the old data before releasing the memory.
Now that we want to implement the wait for readers stage using ref-count on pointers. The protected pointer goes through two states: before update, since it is attached to some placeholders, its ref-count is at least 1 even if no threads hold it; after the update, since the pointer is not anymore attached to the placeholders, its ref-count value reflect the number of still active readers. The nice aspect of this is that starting from the update, the ref-count is now only decreasing, and thus, when the last reader release the pointer, automatic garbage collection frees the memory.
So, if the pointer is visible, you have the guarantee that the count will never get down to 0 and thus it will stay valid, on the other hand, when the pointer has been replaced, no new threads can grab it and increase the counter.
Stated this way, it seems that we have a less difficult synchronization problem: we just need to be sure that counts are correctly handled, and a simple atomic storage can provide that. Are we really safe ?
In parallel computing, issues rise in the details, and in the complexity of transition states. Here, the potential problem may rise when the pointer is replaced. Consider the following schema:
- no reader hold the pointer
- a writer is active and ready to update the pointer
- a new reader arrive and get its hand on the shared pointer before the update
- the writer performs the change, decreasing the ref-counter, at this point, the only remaining reference is in the writer’s hand.
- the writer releases its own copy before the reader had time to increase the counter (the reader may have been scheduled for example)
- Being the last thread holding a reference, the writer thread see the ref-count getting downto 0 and enter in the memory release code
- now, even if the reader succeed at increasing the ref-count, the pointer will be invalidated, causing potential improper dereference.
We're facing a classical race-condition.
In order to prevent that kind of situation, you need lock, or more clever constructions (hey RCU here you are … ), but the ref-count doesn’t help alone. The problem is that a reader need to take two actions: grab the data and increase the counter at the same time, there’s no atomic operations able to do that. Eventually, you can think of a kind of tagged pointer, where the ref-count is contiguously attached to the pointer, that sounds good, but it means that getting the pointer no longer requires one atomic load, but a fail/retry loop of compare-and-swap which will be expensive when in the presence of a lot of readers.
Ref-counting and Lock-free Data Structures
Another use-case we may consider is life-time of memory cells in lock-free data structures. As an example, I’ll consider the classical lock-free queue of
Micheal&Scott Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms.
Micheal&Scott Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms.
In this case we have two problem related to pointers: use after free and ABA.
Let’s have a quick overview of the part of the algorithm that introduce these
issues:
Let’s have a quick overview of the part of the algorithm that introduce these
issues:
- The queue is single linked list with 2 entry points (tail and head/)
- The head points to a recycled sentinel which points to the real top of the queue.
- Update operations are based on compare-and-swap.
- A consumer (after checking for emptyness) will get the value from the next of the head, detach the old head and replace it with its next (recycling the element as a sentinel.)
The problem: an acting consumer grab the head pointer and a pointer to its next element and keep it until it succeeds in updating the head pointer or fail (and the retry its operation.) Consider what happen to the head: when the a consumer thread arrives, the first things it does is to get the head pointer, but in the same time, another active consumer may finish its job and update this pointer. Atomicity, enforce the fact that the new consumer thread will either see the old head or the new head, if it sees the old one, it’ll try to access the content in order to grab the next pointer. Again, in a race condition scenario, if the thread that update the head had time to release the memory cell, the new thread will dereference a freed pointer.
Since the lock-free algorithm relies heavily on compare-and-swap and thus often check pointers, one can avoid the use-after-free by simply recycling the memory cells rather than freeing them. Now, we introduce, or at least we increase the risk of, another problem: ABA.
ABA is a classical problem associated with compare-and-swap updates. Most CAS based algorithms check that a pointer hasn't changed before updating it, in the presence of recycling, it may happen that the same pointer has been detached and then reused while the thread was scheduled. Thus, seeing the same pointer doesn’t mean that it hasn’t change.
Again, can we use ref-count to solve these issues ?
Like before, the idea is that the pointer has two different life: when its attached (and its ref-count will be at least 1) and when it has been detached (and then its ref-count will only decrease.) The problem is still in the transition phase. Just consider the use-after-free scenario: when the new consumer thread get the head pointer, it may fetch a pointer that will be detached immediately after. Once again, if add a ref-count, where is it ? And how can we fetch the pointer and increment the ref-count at the same time so that it won’t be freed ? Race condition, again !
As expected (this isn't a new result), ref-count is not the right tools for non-blocking algorithm.
Solutions
In the previous examples, I describes problems that can’t be solved using ref-counting, but is there any solution anyway ?
RCU, Hazard Pointers and Procrastination Based Programming
Managing life-time of pointers in a (almost) non-blocking manner, can be done using techniques that basically belongs to procrastination or relativistic programming. The base idea is that you don't need to do it as soon as you can, but just wait for a better moment.
RCU is an approach heavily used in the Linux kernel and is becoming available in userland. How does it work ? I’ll write something about it later, but in short, the writer (the one who wants to delete the pointer) waits while readers are still active. How does he now that readers are active ? All threads go through a quiescent state from time to time where they no longer need coherency, all the job of the RCU framework is to provide the simplest possible code (on the reader side) that provides the correct wait period. Things are not exactly simple in userland, but it works. A lot of ressources are available in Introduction to RCU
Hazard Pointers are a little bit more classical. They provide two aspects: deferred deletes and protection for in use pointers. Each thread has a set of hazard pointers (variable shared for reading only) where they put their current pointers; on the delete side, pointers scheduled for delete are accumulated in a wait list, when this list reach a given size, the current thread take the difference between the wait list and the pointers in the hazard pointers of other threads and delete the result. The original article presents most of what you need to know on the subject Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects.
Is it worth the effort ?
I've made some experiment with my own hazard pointers implementation and C++11 shared_ptr, in order to see the impact of synchronization in smart pointer using ref-counting.
The experiment is pretty simple: a bunch of threads reading a shared buffer, eventually another thread comes and updates the buffer (change the pointer). The buffer is not protected by synchronization but we fetch the pointer using atomic load (with full sequential consistency.) As a reference, we have a version with only readers and no extensions related to memory reclamation (not needed in this case.) The two others versions support only reading and sporadic updates, the first one use smart pointers and the second uses hazard pointers.
Hazard pointers add some code to the readers: once the pointer has been fetched and stored in the hazard pointer, we need to check that it hasn’t change. The pointer is only protected when stored in the hazard pointer, meaning that you can have an update between the first fetch and the storage in the HP, with the risk of seeing the pointer invalidated between the two operations.
The read itself only do a kind of strlen on a buffer of 256 bytes, exactly 2²⁴ times, while the reader updates the buffer with a sleeping time of 50 micro-seconds between each update.
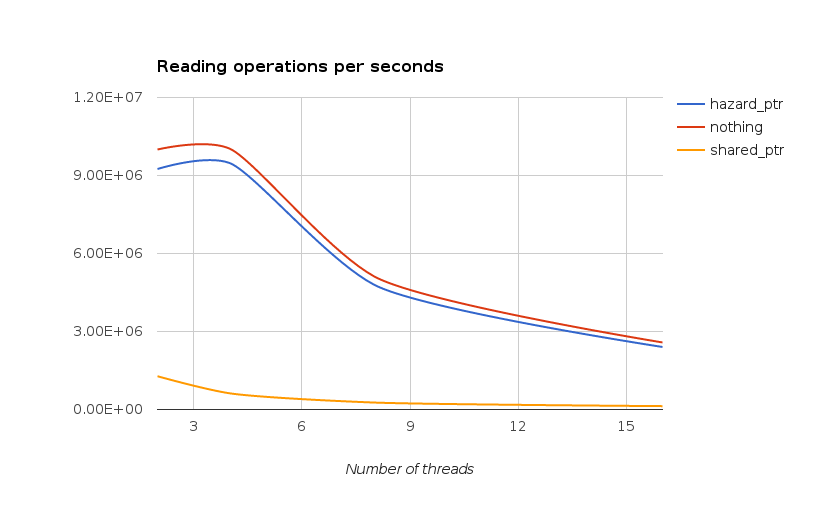
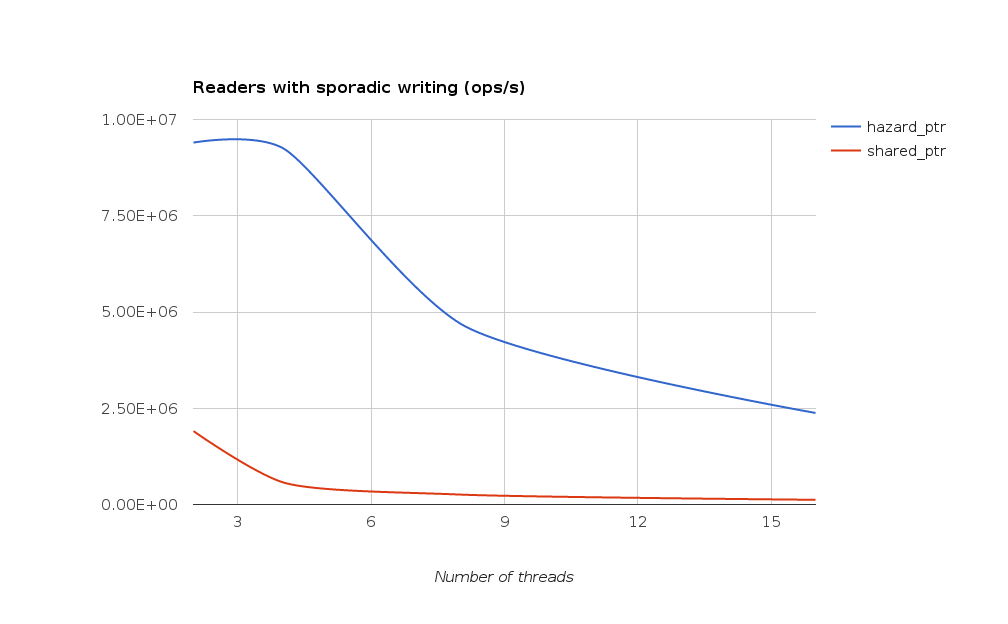
This is a micro-bench, and thus you should take it with the usual care, but results are pretty self explanatory: smart pointers performances are way down below the others.
Experiment were run on a two dual-core CPU (Dual-Core AMD Opteron Processor 2220) thus four physical cores, with 16GB of RAM in two NUMA banks. The code were produced with gcc 5.1.0 using -O3 flag. I use out of the box Archlinux distribution (and thus pre-emptive kernel.) Timings are done inside the code directly using C++11 monotonic wall-clock.
Raw results for reading only cases: the table presents execution time for each version and for different number of threads.
| Version | 2 | 4 | 8 | 16 |
|---|---|---|---|---|
| No sync | 1.67829 | 1.672315 | 3.27503 | 6.50652 |
| shared_ptr | 13.11705 | 26.9322 | 62.7429 | 129.811 |
| Hazard ptr | 1.81462 | 1.769805 | 3.49345 | 6.977785 |
The second table presents results in the presence of a single writer:
| Version | 2 | 4 | 8 | 16 |
|---|---|---|---|---|
| shared_ptr | 8.80095 | 28.9339 | 65.05 | 137.608 |
| Hazard ptr | 1.78479 | 1.81097 | 3.56837 | 7.05612 |
 |
| Read operations per second per thread |
 |
| Read operations per second per thread |
Conclusion
So, while ref-counting can be useful tool in a lot of cases (like in my simple C piece of code) using it in multithreaded environment may become expensive.
I started this article because I was, once again, trap by the false idea that we can use ref-count (in some specific cases) safely, but as you can see, removing constraints doesn’t solve the synchronization issue. While I'm speaking, there isn't official implementation of real non-blocking memory reclamation techniques like hazard pointers. A userland RCU implementation is available (and I’m in the process of writing my own in C++ style) but it’s not really portable (at least, it works on most modern Unixes, but not all architectures.)
There exists other approaches, like tagged pointers, that solves ABA problems in lock-free data structures, but as it seems, deferred memory reclamations seems to be pretty efficient. I strongly encourage you to read RCU papers (both web articles about its uses in Linux and academics ones.) With working RCU, a lot of concurrent accesses problems can be solved easily with almost no specific code and almost no overhead on the reader side.
Subscribe to:
Comments (Atom)